Planet Python
Last update: April 16, 2024 09:43 PM UTC
April 16, 2024
Today, we’re excited to announce a new, improved experience for Python library reference documentation on Microsoft Learn, formerly Microsoft Docs. The new experience is now available for all Microsoft Python libraries on Learn, such as the Azure SDK for Python. In this blog post, we take a closer look at the specific changes made and how they improve the overall experience and accessibility of Python reference documentation on Learn.
Change Summary
The key changes made to Python reference documentation on Learn were improving the navigation experience with the table of contents (TOC), the organization of in-page content, and in-page navigation via the right rail. When combined, these three key changes greatly improve the experience of finding information in Python reference on Learn.
Table of Contents (TOC)
If you’ve used reference documentation before, you’ll know that the TOC serves as a uniquely pivotal tool for navigation between pages. Reference documentation, unlike conceptual articles and tutorials, rarely links together in an easy-to-follow way. This means that the TOC is often the only way for cross-page navigation in reference documentation, making it a key priority for us to get right.
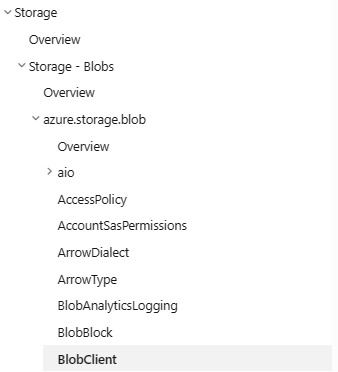
TOC – Before
Previously, the table of contents for Python Reference documentation on Learn had a redundant layer of navigation for package names (in the screenshot below, the azure-storage-blob node), which added confusion for users looking to navigate deeper into the documentation. In addition, the table of contents had package prefixes attached to every item. This led to a cluttered experience, with some items in the TOC taking up two lines of space, further impacting readability and accessibility.

TOC – After
The new TOC design removes the package name overview page and trims the package prefix from TOC items, making it easier to scan and navigate. If you’ve bookmarked a package name overview page, don’t worry, as you’ll be redirected to the package overview page automatically.
In-Page Right Rail
The in-page right rail is a key part of reference documentation, allowing you to navigate in-page and quickly jump to different sections.
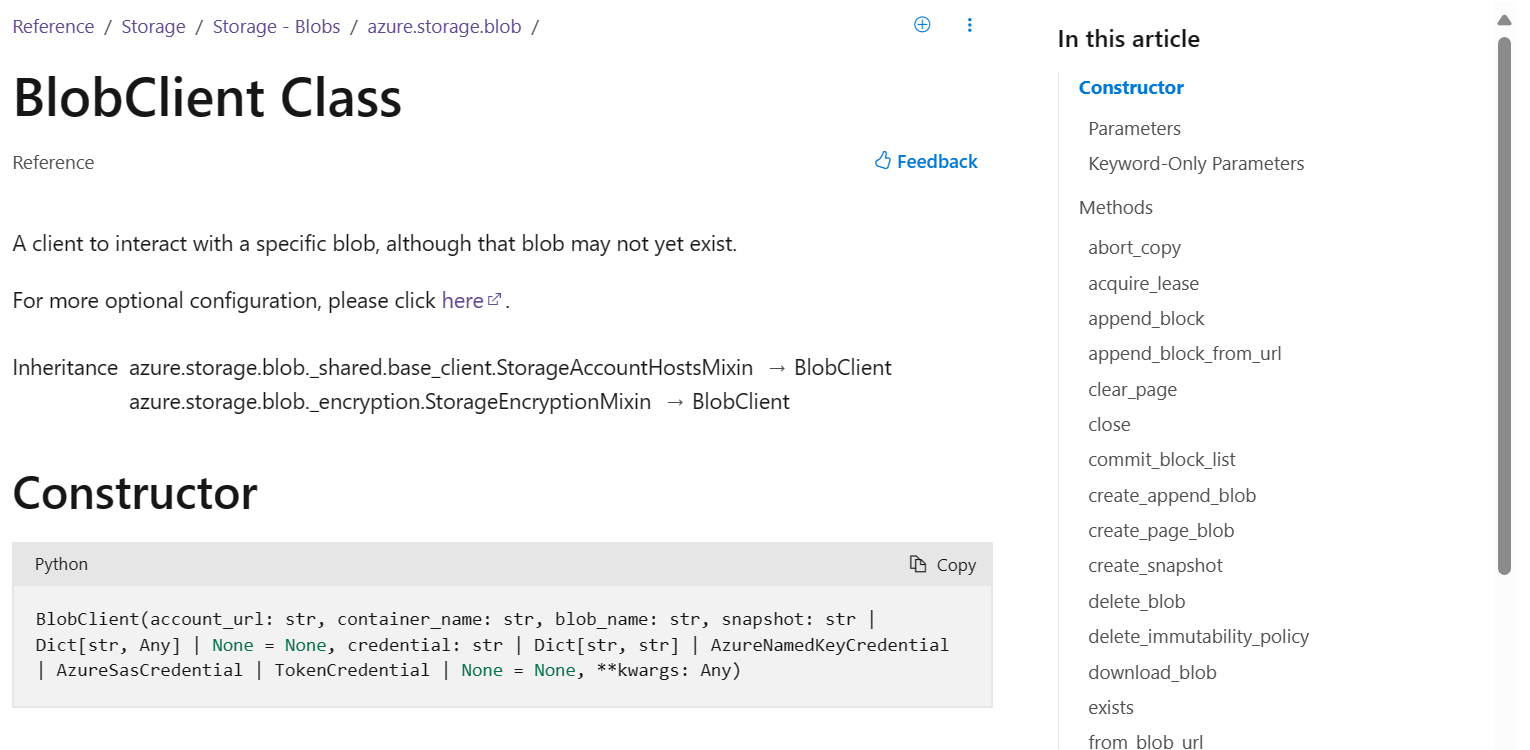
In-Page Right Rail – Before
Before, the right rail wasn’t “sticky”, meaning that once users scrolled on the page, the rail wouldn’t follow them, and the entire right side of the screen would be unused space. Additionally, the right rail links only covered H2 content on the page, resulting in a right rail that didn’t clarify any major details on the page. Finally, the right rail would be collapsed beyond four items, leading to extra effort from the user to see all of the H2 sections on the page. We recognize this design wasn’t consistent with the ways that other Python libraries design their documentation and made updates to better align with design patterns and expectations.
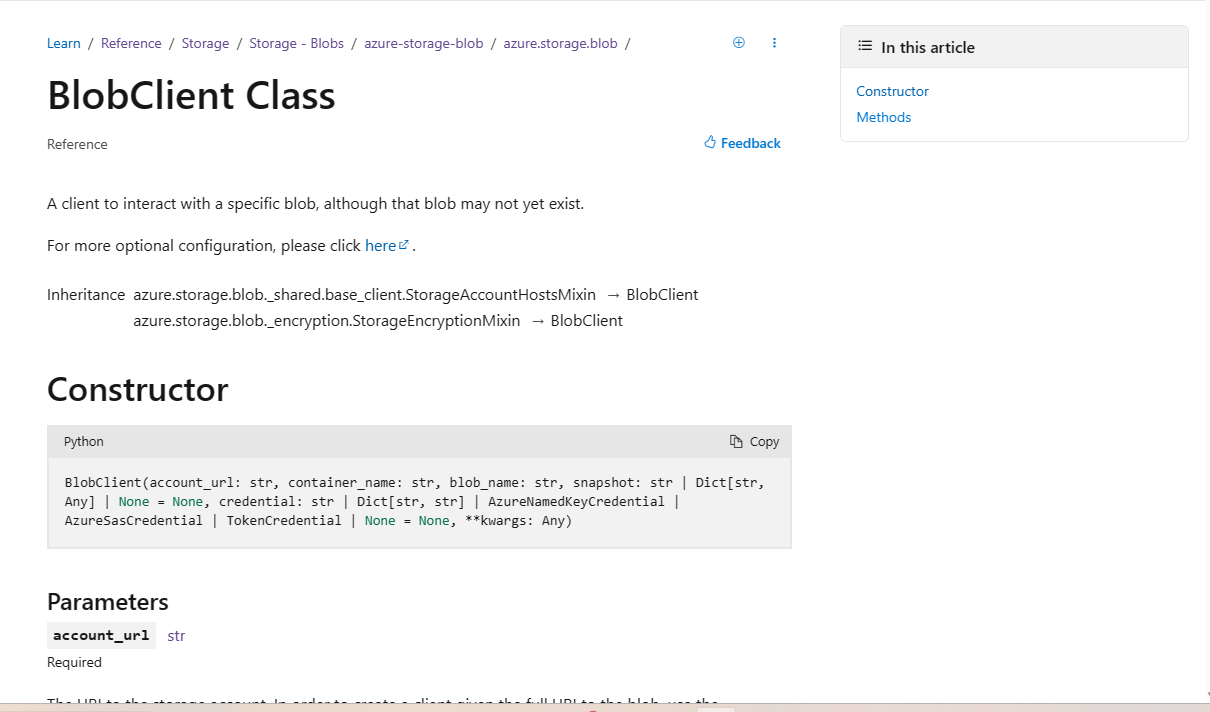
In-Page Right Rail – After
The enhanced experience adds an individually scrollable, sticky right rail with details down to H3s, giving much more detail into what content the page has. The right rail additionally has active highlighting for the current item on the screen, making it easier for you to understand your current position relative to other content.
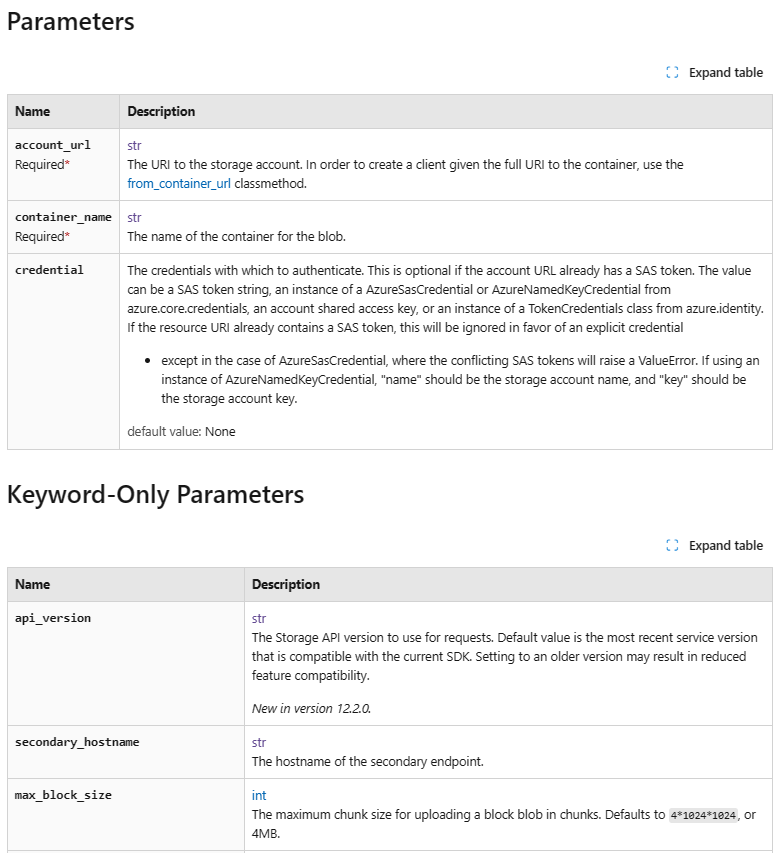
Parameter, Return, and Exception Organization
While the first two major feature changes focus on both overall and in-page navigation, we also identified an opportunity to improve in-page organization as well. When you’re looking at our reference documentation, being able to easily identify key information such as parameters, return values, and exceptions is crucial.
In-Page Organization – Before
Before the updates, these details were listed but not clearly separated between classes, leading to a confusing experience where it’s not clear where items started or ended. Additionally, as a result of the formatting of these values, a significant amount of vertical space was used, leading to a lot of scrolling to find the information needed. Lastly, required parameters, default values, and keyword-only parameters weren’t clearly highlighted to follow accessibility best practices, resulting in extra effort to find crucial information.
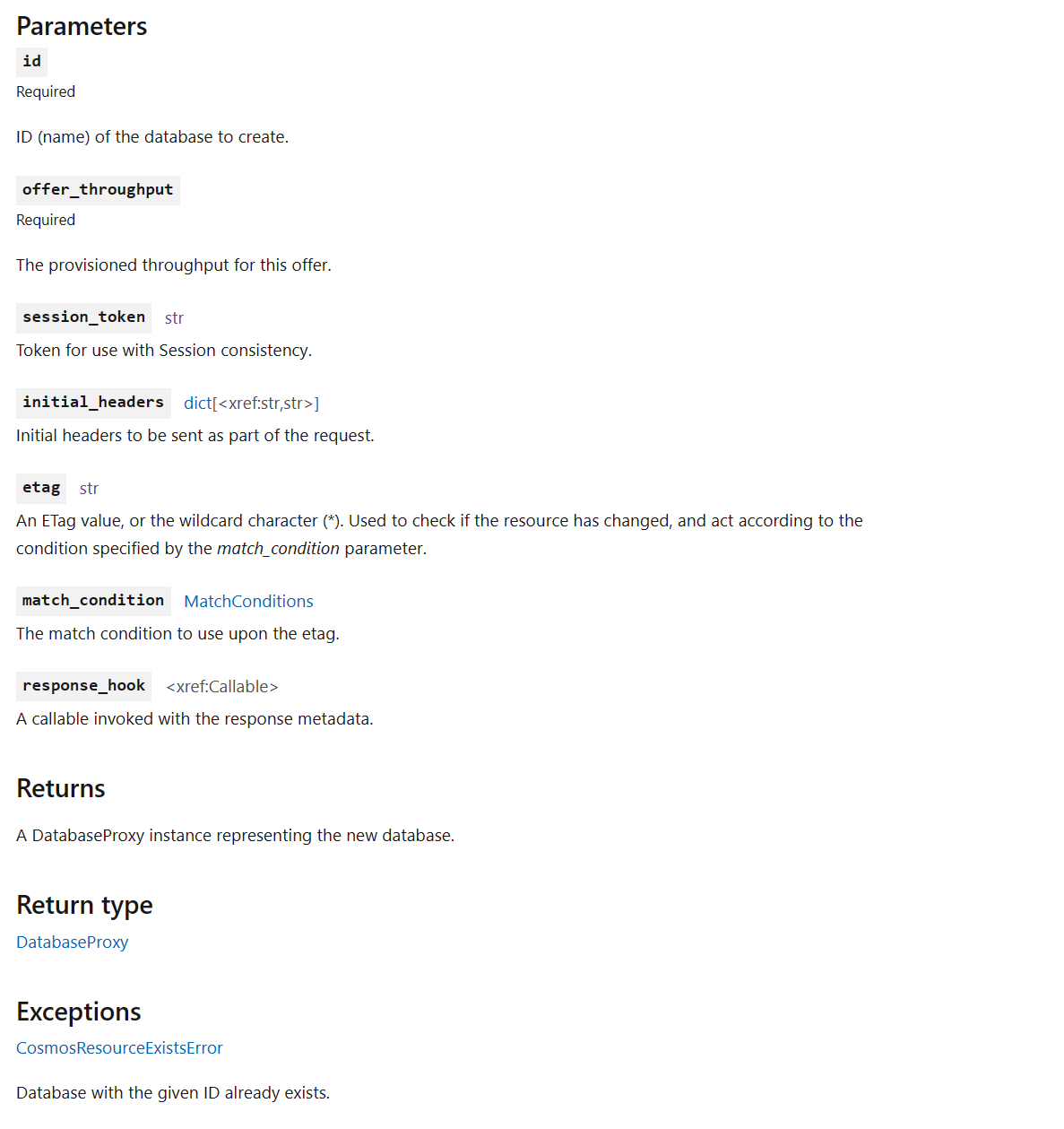
In-Page Organization – After
The new experience organizes parameters, return values, and exceptions into easy-to-scan tables. By using tables, default values, required tags, and types are clearly indicated. The end result is a cleaner and easier-to-use experience for all developers when scrolling through our documentation.
Conclusion
In short, the new Python reference documentation experience on Learn is a major improvement for any developer using Microsoft’s Python libraries. The new TOC, in-page right rail, and in-page organization changes make finding information easier, with an added visual upgrade. We’re excited to continue optimizing the Python developer experience across all of our libraries and tools.
We hope you enjoy the changes! If you have any thoughts, you can leave feedback in the Azure SDK for Python GitHub repo.
The post Glow up! A new look for Python Reference documentation on Microsoft Learn appeared first on Python.
April 16, 2024 09:41 PM UTC
In this post I’ll try to document the journey starting from a WebKit issue and
ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new
feature needed on WebKit side would trigger work …
April 16, 2024 08:15 PM UTC
#625 – APRIL 16, 2024
View in Browser »

Discover the power of Pydantic, Python’s most popular data parsing, validation, and serialization library. In this hands-on tutorial, you’ll learn how to make your code more robust, trustworthy, and easier to debug with Pydantic.
REAL PYTHON
Coding on the web means you have to be more security conscious as everyone has access to your software. This article discusses key steps you can take to help make your code more secure.
ARJAN

With Sentry, you can trace issues from the frontend to the backend—detecting slow and broken code, to fix what’s broken faster. Installing the Python SDK is super easy and PyCoder’s Weekly subscribers get three full months of the team plan. Just use code “pycoder” on signup →
SENTRY sponsor
Michael of TalkPython fame gave this keynote at PyCon Philippines. He addresses topics such as Python trends in code, asyncio, Flask and Django, getting rid of the GIL and more.
MICHAEL KENNEDY video
Discussions
Articles & Tutorials
“Django’s system check framework provides fantastic protection for configuration mishaps. It’s like a targeted linter that runs when you start Django commands.” It also can be a bit slow for large projects. As part of the Django 5.1 release many optimizations have been applied. This blog posts discusses the work involved.
ADAM JOHNSON
“When talking flippantly about programming languages, it’s sometimes useful to glob a bunch of them together based on characteristics, whether superficial or not. This started with jokes about common features of ‘P languages’ like Perl, PHP, Python, JavaScript and Ruby, but you can classify other languages too.”
BRYCE KERLEY
In this video course, you’ll learn how to use Python to generate QR codes, from your standard black-and-white QR codes to beautiful ones with your favorite colors. You’ll learn how to format QR codes, rotate them, and even replace the static background with moving images.
REAL PYTHON course
Sometimes teachers or mentors ask students to contribute to an open source project, without the context of what that entails. This opinion piece covers just how much noise that causes for the projects and why you shouldn’t do it unless you truly mean to contribute.
DAVID LORD
Ashlynn ran into a problem where her code was initializing a connection to the Google Cloud API before the credentials for it had been imported. This blog post covers the problem and how she got around it.
ASHLYNN ANTROBUS
For a year and a half, Rodrigo worked at Textualize the company behind the popular open source Python projects Rich and Textual. This blog post talks about what he learned while he was there.
RODRIGO GIRÃO SERRÃO
Like many of us, Pawel uses f-strings a lot. Even with frequent use, it can be hard to remember how the formatting syntax works. This post covers some of the more common formats around.
PAWEL JASTRZEBSKI
What’s it mean to write clean code? What is clean Python code, specifically? This article talks about how to write code that is easier to read and the tools you can use to get there.
NIK TOMAZIC
Were you in the path of the eclipse last week? Would you like to figure out if you’ll be in the next one? This article shows you how using the Astropy library.
ERIK BERNHARDSSON
This guide walks you through transcribing video using the OpenAI Whisper model and seamlessly adding subtitles with FFmpeg tool.
EDITFRAME
Projects & Code
Events
Happy Pythoning!
This was PyCoder’s Weekly Issue #625.
View in Browser »

[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
April 16, 2024 07:30 PM UTC
The time complexity of common operations on Python's many data structures.
Time Complexity ⏱️
Time complexity is one of those Computer Science concepts that's scary in its purest form, but often fairly practical as a rough "am I doing this right" measurement.
In the words of Ned Batchelder, time complexity is all about "how your code slows as your data grows".
Time complexity is usually discussed in terms of "Big O" notation.
This is basically a way to discuss the order of magnitude for a given operation while ignoring the exact number of computations it needs.
In "Big O" land, we don't care if something is twice as slow, but we do care whether it's n times slower where n is the length of our list/set/slice/etc.
Here's a graph of the common time complexity curves:
Remember that these lines are simply about orders of magnitude.
If an operation is on the order of n, that means 100 times more data will slow things down about 100 times.
If an operation is on the order of n² (that's n*n), that means 100 times more data will slow things down 100*100 times.
I usually think about those curves in terms of what would happen if we suddenly had 1,000 times more data to work with:
O(1): no change in time (constant time!)O(log n): ~10 times slow downO(n): 1,000 times slow downO(n log n): 10,000 times slow downO(n²): 1,000,000 times slow down! 😲
With that very quick recap behind us, let's take a look at the relative speeds of all common operations on each of Python's data structures.
List 📋
Python's lists are similar to …
April 16, 2024 03:00 PM UTC
In your Python journey, you’ll come across situations where you need to signal that something is going wrong in your code. For example, maybe a file doesn’t exist, a network or database connection fails, or your code gets invalid input. A common approach to tackle these issues is to raise an exception, notifying the user that an error has occurred. That’s what Python’s raise statement is for.
Learning about the raise statement allows you to effectively handle errors and exceptional situations in your code. This way, you’ll develop more robust programs and higher-quality code.
In this video course, you’ll learn how to:
- Raise exceptions in Python using the
raise statement
- Decide which exceptions to raise and when to raise them in your code
- Explore common use cases for raising exceptions in Python
- Apply best practices for raising exceptions in your Python code
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
April 16, 2024 02:00 PM UTC
Do you know what custom GPTs are? They're configurable and shareable chat experiences with a name, logo, custom instructions, conversation starters, access to OpenAI tools, and custom API actions. And, you can build them with Python! Ian Maurer has been doing just that and is here to share his experience building them.<br/>
<br/>
<strong>Episode sponsors</strong><br/>
<br/>
<a href='https://talkpython.fm/sentry'>Sentry Error Monitoring, Code TALKPYTHON</a><br>
<a href='https://talkpython.fm/neo4j-notes'>Neo4j</a><br>
<a href='https://talkpython.fm/training'>Talk Python Courses</a><br/>
<br/>
<strong>Links from the show</strong><br/>
<br/>
<div><b>Ian on Twitter</b>: <a href="https://twitter.com/imaurer" target="_blank" rel="noopener">@imaurer</a><br/>
<br/>
<b>Mobile Navigation</b>: <a href="https://openai.com/blog/introducing-gpts" target="_blank" rel="noopener">openai.com</a><br/>
<b>What is a Custom GPT?</b>: <a href="https://www.imaurer.com/what-is-a-custom-gpt/" target="_blank" rel="noopener">imaurer.com</a><br/>
<b>Mobile Navigation</b>: <a href="https://openai.com/blog/introducing-the-gpt-store" target="_blank" rel="noopener">openai.com</a><br/>
<b>FuzzTypes: Pydantic library for auto-correcting types</b>: <a href="https://github.com/genomoncology/FuzzTypes" target="_blank" rel="noopener">github.com</a><br/>
<b>pypi-gpt</b>: <a href="https://github.com/imaurer/pypi-gpt" target="_blank" rel="noopener">github.com</a><br/>
<b>marvin</b>: <a href="https://github.com/prefecthq/marvin" target="_blank" rel="noopener">github.com</a><br/>
<b>instructor</b>: <a href="https://github.com/jxnl/instructor" target="_blank" rel="noopener">github.com</a><br/>
<b>outlines</b>: <a href="https://github.com/outlines-dev/outlines" target="_blank" rel="noopener">github.com</a><br/>
<b>llamafile</b>: <a href="https://github.com/Mozilla-Ocho/llamafile" target="_blank" rel="noopener">github.com</a><br/>
<b>llama-cpp-python</b>: <a href="https://github.com/abetlen/llama-cpp-python" target="_blank" rel="noopener">github.com</a><br/>
<b>LLM Dataset</b>: <a href="https://llm.datasette.io/en/stable/index.html" target="_blank" rel="noopener">llm.datasette.io</a><br/>
<b>Plugin directory</b>: <a href="https://llm.datasette.io/en/stable/plugins/directory.html" target="_blank" rel="noopener">llm.datasette.io</a><br/>
<b>Data exploration at your fingertips.</b>: <a href="https://www.visidata.org/" target="_blank" rel="noopener">visidata.org</a><br/>
<b>hottest new programming language is English</b>: <a href="https://twitter.com/karpathy/status/1617979122625712128" target="_blank" rel="noopener">twitter.com</a><br/>
<b>OpenAI & other LLM API Pricing Calculator</b>: <a href="https://docsbot.ai/tools/gpt-openai-api-pricing-calculator" target="_blank" rel="noopener">docsbot.ai</a><br/>
<b>Vector DB Comparison</b>: <a href="https://vdbs.superlinked.com/" target="_blank" rel="noopener">vdbs.superlinked.com</a><br/>
<b>bpytop</b>: <a href="https://github.com/aristocratos/bpytop" target="_blank" rel="noopener">github.com</a><br/>
<b>Source Graph</b>: <a href="https://about.sourcegraph.com/cody" target="_blank" rel="noopener">about.sourcegraph.com</a><br/>
<b>Watch this episode on YouTube</b>: <a href="https://www.youtube.com/watch?v=FwmbJiKdAG0" target="_blank" rel="noopener">youtube.com</a><br/>
<b>Episode transcripts</b>: <a href="https://talkpython.fm/episodes/transcript/456/building-gpt-actions-with-fastapi-and-pydantic" target="_blank" rel="noopener">talkpython.fm</a><br/>
<br/>
<b>--- Stay in touch with us ---</b><br/>
<b>Subscribe to us on YouTube</b>: <a href="https://talkpython.fm/youtube" target="_blank" rel="noopener">youtube.com</a><br/>
<b>Follow Talk Python on Mastodon</b>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" rel="noopener"><i class="fa-brands fa-mastodon"></i>talkpython</a><br/>
<b>Follow Michael on Mastodon</b>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" rel="noopener"><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
April 16, 2024 08:00 AM UTC
<strong>Topics covered in this episode:</strong><br>
<ul>
<li><a href="https://stefaniemolin.com/articles/devx/pre-commit/setup-guide/">How to Set Up Pre-Commit Hooks A step-by-step guide to installing and configuring pre-commit hooks on your project</a>.</li>
<li><a href="https://difftastic.wilfred.me.uk"><strong>difftastic</strong></a></li>
<li><a href="https://quarto.org"><strong>Quarto</strong></a></li>
<li><a href="https://github.com/saurabh0719/constable"><strong>constable</strong></a></li>
<li><strong>Extras</strong></li>
<li><strong>Joke</strong></li>
</ul><a href='https://www.youtube.com/watch?v=4PoBtLFRWGU' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="379">Watch on YouTube</a><br>
<p><strong>About the show</strong></p>
<p>Sponsored by us! Support our work through:</p>
<ul>
<li>Our <a href="https://training.talkpython.fm/"><strong>courses at Talk Python Training</strong></a></li>
<li><a href="https://courses.pythontest.com/p/the-complete-pytest-course"><strong>The Complete pytest Course</strong></a></li>
<li><a href="https://www.patreon.com/pythonbytes"><strong>Patreon Supporters</strong></a></li>
</ul>
<p><strong>Connect with the hosts</strong></p>
<ul>
<li>Michael: <a href="https://fosstodon.org/@mkennedy"><strong>@mkennedy@fosstodon.org</strong></a></li>
<li>Brian: <a href="https://fosstodon.org/@brianokken"><strong>@brianokken@fosstodon.org</strong></a></li>
<li>Show: <a href="https://fosstodon.org/@pythonbytes"><strong>@pythonbytes@fosstodon.org</strong></a></li>
</ul>
<p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually Tuesdays at 11am PT. Older video versions available there too.</p>
<p>Finally, if you want an artisanal, hand-crafted digest of every week of </p>
<p>the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it.</p>
<p><strong>Michael #1:</strong> <a href="https://stefaniemolin.com/articles/devx/pre-commit/setup-guide/">How to Set Up Pre-Commit Hooks A step-by-step guide to installing and configuring pre-commit hooks on your project</a>.</p>
<ul>
<li>by <a href="https://stefaniemolin.com/"><strong>Stefanie Molin</strong></a></li>
<li>Pre-commit hooks are code checks that run as part of the “pre-commit” stage of the git commit process. </li>
<li>If any of these checks fail, git aborts the commit</li>
<li>Sometimes, we need to bypass the hooks temporarily. For these instances, we can pass the --no-verify option when we run git commit</li>
</ul>
<p><strong>Brian #2:</strong> <a href="https://difftastic.wilfred.me.uk"><strong>difftastic</strong></a></p>
<ul>
<li>Found this a couple years ago, but really using it a lot now.</li>
<li>Excellent structurally diff tool that compares code based on syntax, not line by line.</li>
</ul>
<p><strong>Michael #3:</strong> <a href="https://quarto.org"><strong>Quarto</strong></a></p>
<ul>
<li>via Mathias Johansson</li>
<li>An open-source scientific and technical publishing system</li>
<li>Transforming a notebook into a pdf / HTML / MS Word / ePub with minimal effort, or even all formats at once.</li>
<li>Author using <a href="https://jupyter.org/">Jupyter</a> notebooks or with plain text markdown in your favorite editor.</li>
<li>Write using <a href="https://pandoc.org/">Pandoc</a> markdown, including equations, citations, crossrefs, figure panels, callouts, advanced layout, and more.</li>
</ul>
<p><strong>Brian #4:</strong> <a href="https://github.com/saurabh0719/constable"><strong>constable</strong></a></p>
<ul>
<li>“inserts print statements directly into the AST at runtime “</li>
<li>“If you find yourself aimlessly adding print statements while debugging your code, this is for you. !”</li>
<li>Add decorators like @constable.trace('a', 'b') to functions and you’ll get nice output showing when and how a and b changed.</li>
<li>see also <a href="https://github.com/gruns/icecream">icecream</a> for another fun debugging with print project.</li>
</ul>
<p><strong>Extras</strong> </p>
<p>Brian:</p>
<ul>
<li><a href="https://www.reddit.com/r/Python/comments/1bt7rnw/pointerspy_being_added_to_the_standard_library/"><strong>pointers being added to the standard library</strong></a>
<ul>
<li>A couple weeks old, but still worth covering</li>
<li>Guido’s take on adding this, "Why the hell not?"</li>
</ul></li>
</ul>
<p>Michael:</p>
<ul>
<li><a href="https://docs.python.org/release/3.12.3/whatsnew/changelog.html#python-3-12-2">Python 3.12.3 is out</a></li>
</ul>
<p><strong>Joke:</strong> <a href="https://twitter.com/hynek/status/1777377316269883420">Hugo SciFi Award</a></p>
April 16, 2024 08:00 AM UTC
April 15, 2024
I’ve added experimental function and class coverage reports to coverage.py.
I’d like feedback
about whether they behave the way you want them to.
I haven’t made a PyPI release. To try the new reports, install coverage from
GitHub. Be sure to include the hash:
$ python3 -m pip install git+https://github.com/nedbat/coveragepy@f10c455b7c8fd26352de#egg=coverage==0.0
Then run coverage and make an HTML report as you usually do. You should
have two new pages, not linked from the index page (yet).
“htmlcov/function_index.html” is the function coverage report, and the classes
are in “htmlcov/class_index.html”.
I had to decide how to categorize nested functions and classes. Inner
functions are not counted as part of their outer functions. Classes consist of
the executable lines in their methods, but not lines outside of methods, because
those lines run on import. Each file has an entry in the function report for
all of the lines outside of any function, called “(no function)”. The class
report has “(no class)” entries for lines outside of any classes.
The result should be that every line is part of one function, or the “(no
function)” entry, and every line is part of one class, or the “(no class)”
entry. This is what made sense to me, but maybe there’s a compelling reason to
do it differently.
The reports have a sortable column for the file name, and a sortable column
for the function or class. Where functions or classes are nested, the name is a
dotted sequence, but is sorted by only the last component. Just like the
original file listing page, the new pages can be filtered to focus on areas of
interest.
You can look at some sample reports:
It would be helpful if you could give me
feedback on the
original issue about some questions:
- Is it useful to have “(no function)” and “(no class)” entries or is it just
distracting pedantry? With the entries, the total is the same as the file
report, but they don’t seem useful by themselves.
- Does the handling of nested functions and classes make sense?
- Should these reports be optional (requested with a switch) or always
produced?
- Is it reasonable to produce one page with every function? How large does a
project have to get before that’s not feasible or useful?
- And most importantly: do these reports help you understand how to improve
your code?
This is only in the HTML report for now, but we can do more in the future.
Other ideas
about improvements are of course welcome. Thanks!
April 15, 2024 08:02 PM UTC
Are you a regular Django user? Do you find yourself wanting to decouple your back end and front end? Do you want to handle data persistence in the API while you display the data in a single-page app (SPA) in the browser using a JavaScript framework like React or Vue?
If you answered yes to any of these questions, then you’re in luck. This tutorial will take you through the process of building a Django blog back end and a Vue front end, using GraphQL to communicate between them.
Projects are an effective way to learn and solidify concepts. This tutorial is structured as a step-by-step project so you can learn in a hands-on way and take breaks as needed.
In this tutorial, you’ll learn how to:
- Translate your Django models into a GraphQL API
- Run the Django server and a Vue application on your computer at the same time
- Administer your blog posts in the Django admin
- Consume a GraphQL API in Vue to show data in the browser
You can download all the source code you’ll use to build your Django blog application by clicking the link below:
Demo: A Django Blog Admin, a GraphQL API, and a Vue Front End
Blog applications are a common starter project because they involve create, read, update, and delete (CRUD) operations. In this project, you’ll use the Django admin to do the heavy CRUD lifting and you’ll focus on providing a GraphQL API for your blog data.
You’ll use Vue.js 3 and its composition API for the front end of your blog. Vue lets you create dynamic interfaces pretty smoothly, thanks to its reactive data binding and easy-to-manage components. Plus, since you’re dealing with data from a GraphQL API, you can leverage the Vue Apollo plugin.
Here’s a demonstration of the completed project in action:
Next, you’ll make sure you have all the necessary background information and tools before you dive in and build your blog application.
Project Overview
For this project, you’ll create a small blogging application with some rudimentary features:
- Authors can write many posts.
- Posts can have many tags and can be either published or unpublished.
You’ll build the back end of this blog in Django, complete with an admin for adding new blog content. Then you’ll expose the content data as a GraphQL API and use Vue to display that data in the browser.
You’ll accomplish this in several high-level steps. At the end of each step, you’ll find a link to the source code for that stage of the project.
If you’re curious about how the source code for each step looks, then you can click the link below:
Prerequisites
You’ll be best equipped for this tutorial if you already have a solid foundation in some web application concepts. You should understand how HTTP requests and responses and APIs work. You can check out Python & APIs: A Winning Combo for Reading Public Data to understand the details of using GraphQL APIs vs REST APIs.
Because you’ll use Django to build the back end for your blog, you’ll want to be familiar with starting a Django project and customizing the Django admin. If you haven’t used Django much before, you might also want to try building another Django-only project first. For a good introduction, check out Get Started with Django Part 1: Build a Portfolio App.
And because you’ll be using Vue on the front end, some experience with JavaScript will also help. If you’ve only used a JavaScript framework like jQuery in the past, the Vue introduction is a good foundation.
Familiarity with JSON is also important because GraphQL queries are JSON-like and return data in JSON format. You can read about Working with JSON Data in Python for an introduction.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
April 15, 2024 02:00 PM UTC
The following text is in German, since we're announcing a regional user group meeting in Düsseldorf, Germany.
Ankündigung
Das nächste Python Meeting Düsseldorf findet an folgendem Termin statt:
17.04.2024, 18:00 Uhr
Raum 1, 2.OG im Bürgerhaus Stadtteilzentrum Bilk
Düsseldorfer Arcaden, Bachstr. 145, 40217 Düsseldorf
Programm
Bereits angemeldete Vorträge
- Marc-André Lemburg:
Advanced parsing structured data with Python's new match statement
- Jens Diemer:
Anbindung von Tinkerforge in Home Assistant
- Charlie Clark:
Eine kleine Datenanalyse
- Detlef Lannert:
Überblick über CLI-Frameworks
Weitere Vorträge können gerne noch angemeldet werden. Bei Interesse, bitte unter
info@pyddf.de melden.
Startzeit und Ort
Wir treffen uns um 18:00 Uhr im Bürgerhaus in den
Düsseldorfer Arcaden.
Das Bürgerhaus teilt sich den Eingang mit dem Schwimmbad und befindet
sich an der Seite der Tiefgarageneinfahrt der Düsseldorfer Arcaden.
Über dem Eingang steht ein großes "Schwimm’ in Bilk" Logo. Hinter der Tür
direkt links zu den zwei Aufzügen, dann in den 2. Stock hochfahren. Der
Eingang zum Raum 1 liegt direkt links, wenn man aus dem Aufzug kommt.
>>> Eingang in Google Street View
⚠️ Wichtig: Bitte nur dann anmelden, wenn ihr absolut
sicher seid, dass ihr auch kommt. Angesichts der begrenzten Anzahl Plätze, haben
wir kein Verständnis für kurzfristige Absagen oder No-Shows.
Einleitung
Das Python Meeting Düsseldorf ist eine regelmäßige Veranstaltung in Düsseldorf, die sich an Python Begeisterte aus der Region wendet.
Einen guten Überblick über die Vorträge bietet unser
PyDDF YouTube-Kanal, auf dem wir Videos der Vorträge nach den Meetings veröffentlichen.
Veranstaltet wird das Meeting von der eGenix.com GmbH, Langenfeld, in Zusammenarbeit mit Clark Consulting & Research, Düsseldorf:
Format
Das Python Meeting Düsseldorf nutzt eine Mischung aus (Lightning) Talks und offener Diskussion.
Vorträge können vorher angemeldet werden, oder auch spontan
während des Treffens eingebracht werden. Ein Beamer mit HDMI und FullHD Auflösung
steht zur Verfügung.
(Lightning) Talk Anmeldung bitte formlos per EMail an info@pyddf.de
Kostenbeteiligung
Das Python Meeting Düsseldorf wird von Python Nutzern für Python Nutzer veranstaltet.
Da Tagungsraum, Beamer, Internet und Getränke Kosten produzieren,
bitten wir die Teilnehmer um einen Beitrag in Höhe von EUR 10,00 inkl.
19% Mwst. Schüler und Studenten zahlen EUR 5,00 inkl.
19% Mwst.
Wir möchten alle Teilnehmer bitten, den Betrag in bar mitzubringen.
Anmeldung
Da wir nur 25 Personen in dem angemieteten Raum empfangen können, möchten wir bitten, sich vorher anzumelden.
Meeting Anmeldung bitte per Meetup
Weitere Informationen
Weitere Informationen finden Sie auf der Webseite des Meetings:
https://pyddf.de/
Viel Spaß !
Marc-Andre Lemburg, eGenix.com
April 15, 2024 08:00 AM UTC
2024-04-15, by Dariusz Suchojad


An integral part of
Zato, its scalable, service-oriented scheduler makes it is possible to execute high-level API integration processes as background tasks. The scheduler runs periodic jobs which in turn trigger services and services are what is used to integrate systems.
Integration process
In this article we will check how to use the scheduler with three kinds of jobs, one-time, interval-based and Cron-style ones.
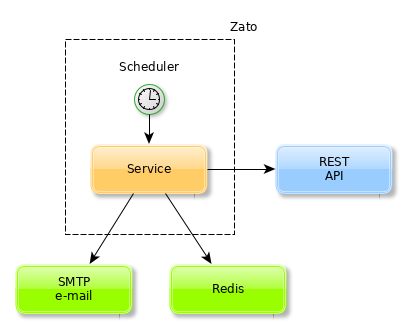
What we want to achieve is a sample yet fairly common use-case:
- Periodically consult a remote REST endpoint for new data
- Store data found in Redis
- Push data found as an e-mail attachment
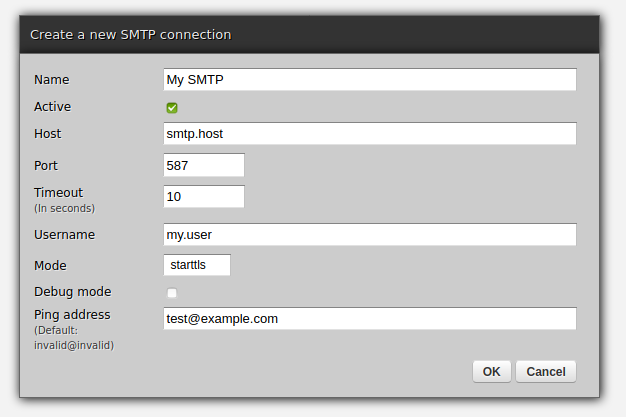
Instead of, or in addition to, Redis or e-mail, we could use SQL and SMS, or MongoDB and AMQP or anything else - Redis and e-mail are just example technologies frequently used in data synchronisation processes that we use to highlight the workings of the scheduler.
No matter the input and output channels, the scheduler works always the same - a definition of a job is created and the job's underlying service is invoked according to the schedule. It is then up to the service to perform all the actions required in a given integration process.
Python code
Our integration service will read as below:
# -*- coding: utf-8 -*-
# Zato
from zato.common.api import SMTPMessage
from zato.server.service import Service
class SyncData(Service):
name = 'api.scheduler.sync'
def handle(self):
# Which REST outgoing connection to use
rest_out_name = 'My Data Source'
# Which SMTP connection to send an email through
smtp_out_name = 'My SMTP'
# Who the recipient of the email will be
smtp_to = 'hello@example.com'
# Who to put on CC
smtp_cc = 'hello.cc@example.com'
# Now, let's get the new data from a remote endpoint ..
# .. get a REST connection by name ..
rest_conn = self.out.plain_http[rest_out_name].conn
# .. download newest data ..
data = rest_conn.get(self.cid).text
# .. construct a new e-mail message ..
message = SMTPMessage()
message.subject = 'New data'
message.body = 'Check attached data'
# .. add recipients ..
message.to = smtp_to
message.cc = smtp_cc
# .. attach the new data to the message ..
message.attach('my.data.txt', data)
# .. get an SMTP connection by name ..
smtp_conn = self.email.smtp[smtp_out_name].conn
# .. send the e-mail message with newest data ..
smtp_conn.send(message)
# .. and now store the data in Redis.
self.kvdb.conn.set('newest.data', data)
Now, we just need to make it run periodically in background.
Mind the timezone
In the next steps, we will use
the Zato Dashboard
to configure new jobs for the scheduler.
Keep it mind that any date and time that you enter in web-admin is always interepreted to be in your web-admin user's timezone and this applies to the scheduler too - by default the timezone is UTC. You can change it by clicking Settings and picking the right timezone to make sure that the scheduled jobs run as expected.
It does not matter what timezone your Zato servers are in - they may be in different ones than the user that is configuring the jobs.
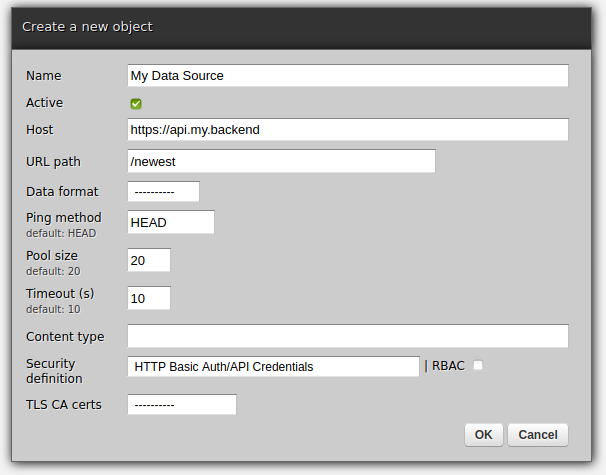
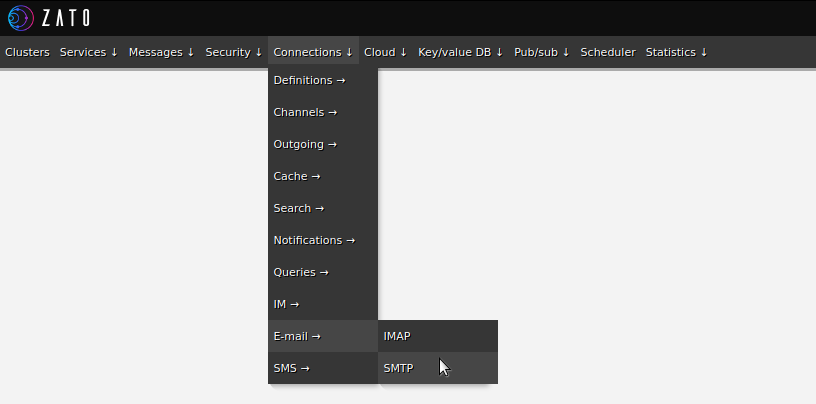
Endpoint definitions
First, let's use web-admin to define the endpoints that the service uses. Note that Redis does not need an explicit declaration because it is always available under "self.kvdb" in each service.
- Configuring outgoing REST APIs
Now, we can move on to the actual scheduler jobs.
Three types of jobs
To cover different integration needs, three types of jobs are available:
- One-time - fires once only at a specific date and time and then never runs again
- Interval-based - for periodic processes, can use any combination of weeks, days, hours, minutes and seconds for the interval
- Cron-style - similar to interval-based but uses the syntax of Cron for its configuration

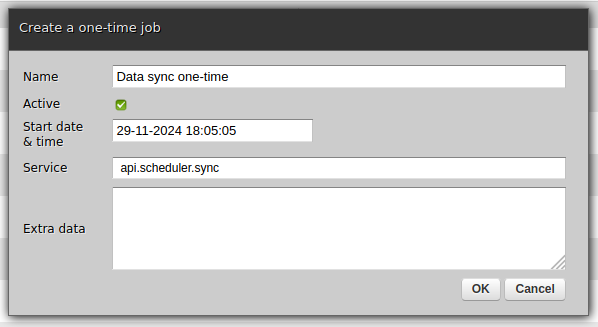
One-time
Select one-time if the job should not be repeated after it runs once.
Interval-based
Select interval-based if the job should be repeated periodically. Note that such a job will by default run indefinitely but you can also specify after how many times it should stop, letting you to express concepts such as "Execute once per hour but for the next seven days".
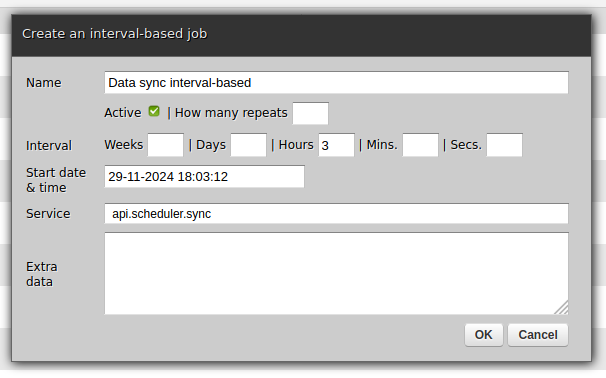
Cron-style
Select cron-style if you are already familiar with the syntax of
Cron
or if you have some Cron tasks that you would like to migrate to Zato.
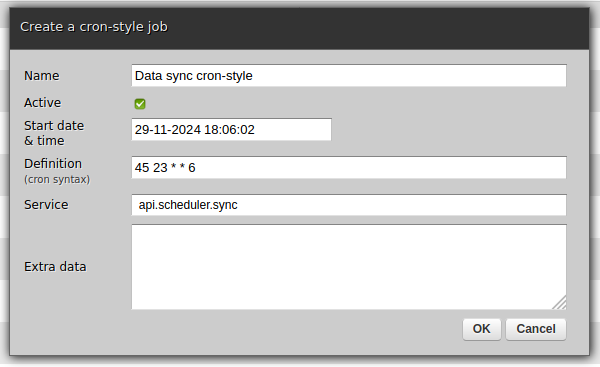
Running jobs manually
At times, it is convenient to run a job on demand, no matter what its schedule is and regardless of what type a particular job is. Web-admin lets you always execute a job directly. Simply find the job in the listing, click "Execute" and it will run immediately.
It is very often useful to provide additional context data to a service that the scheduler runs - to achieve it, simply enter any arbitrary value in the "Extra" field when creating or an editing a job in web-admin.
Afterwards, that information will be available as self.request.raw_request in the service's handle method.
Reusability
There is nothing else required - all is done and the service will run in accordance with a job's schedule.
Yet, before concluding, observe that our integration service is completely reusable - there is nothing scheduler-specific in it despite the fact that we currently run it from the scheduler.
We could now invoke the service from command line. Or we could mount it on a REST, AMQP, WebSocket or trigger it from any other channel - exactly the same Python code will run in exactly the same fashion, without any new programming effort needed.
April 15, 2024 08:00 AM UTC
April 12, 2024
What is error culture, and how do you avoid it within your organization? How do you navigate alert and notification fatigue? Hey, it's episode #200! Real Python's editor-in-chief, Dan Bader, joins us this week to celebrate. Christopher Trudeau also returns to bring another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
April 12, 2024 12:00 PM UTC
There is no such thing as a “root field”.
There is a common - seemingly universal - misconception that GraphQL root fields are somehow special, in both usage and implementation. The better conceptual model is that there are root types, and all types have fields. The difference is not just semantics; it leads to actual misunderstandings.
Multiple queries
A common beginner question is “can there be multiple queries in a request”. The question would be better phrased as “can multiple fields on the root query type be requested”. The answer is of course, because requesting multiple fields on a type is normal. The implementation would have to go out of its way to restrict that behavior on just the root type. The only need for further clarity would be to introduce aliases for duplicate fields.
Flat namespace
GraphQL types share a global namespace, causing conflicts when federating multiple graphs. Nothing can be done about that unless GraphQL adopts namespaces.
But many APIs design the root query type to have unnecessarily flat fields. One often sees a hierarchy of types and fields below the root, but the top-level fields resemble a loose collections of functions. Verbs at the top level; nouns the rest of the way down. This design choice appears to be in a feedback loop with the notion of “root fields”.
Even the convention of calling the root query type Query demonstrates a lack of specificity. In a service-oriented architecture, a particular service might be more narrowly defined.
Mutations
Top-level mutation fields are special in one aspect: they are executed in order. This has resulted in even flatter namespaces for mutations,
mutation {
createUser # executed first
deleteUser
}
This is not necessary, but seems widely believed that it is. Nested mutations work just fine.
mutation {
user {
create # executed in arbitrary order
delete
}
}
If the underlying reason is truly execution order, the client could be explicit instead.
mutation {
created: user { # executed first
create
}
deleted: user {
delete
}
}
There is no reason it has to influence API design.
Static methods
At the library level, the effect is top-level resolvers are implemented as functions (or static methods), whereas all other resolver are methods. This may lead to redundant or inefficient implementations, is oddly inconsistent, and is contrary to the documentation.
A resolver function receives four arguments:
obj The previous object, which for a field on the root Query type is often not used.
Sure, “often not used” by the developer of the API. That does not mean “should be unset” by the GraphQL library, but that is what has happened. Some libraries even exclude the object parameter entirely. In object-oriented libraries like strawberry, the code looks unnatural.
import strawberry
@strawberry.type
class Query:
@strawberry.field
def instance(self) -> bool | None:
return None if self is None else isinstance(self, Query)
schema = strawberry.Schema(Query)
query = '{ instance }'
schema.execute_sync(query).data
Strawberry allows omitting self for this reason, creating an implicit staticmethod.
Root values
Libraries which follow the reference javascript implementation allow setting the root value explicitly.
schema.execute_sync(query, root_value=Query()).data
Strawberry unofficially supports supplying an instance, but it has no effect.
schema = strawberry.Schema(Query())
schema.execute_sync(query).data
And of course self can be of any type.
schema.execute_sync(query, root_value=...).data
Moreover, the execute functions are for internal usage. Each library will vary in how to configure the root in a production application. Strawberry requires subclassing the application type.
import strawberry.asgi
class GraphQL(strawberry.asgi.GraphQL):
def __init__(self, root):
super().__init__(strawberry.Schema(type(root)))
self.root_value = root
async def get_root_value(self, request):
return self.root_value
Example
Consider a more practical example where data is loaded, and clearly should not be reloaded on each request.
@strawberry.type
class Dictionary:
def __init__(self, source='/usr/share/dict/words'):
self.words = {line.strip() for line in open(source)}
@strawberry.field
def is_word(self, text: str) -> bool:
return text in self.words
Whether Dictionary is the query root - or attached to the query root - it should be instantiated only once. Of course it can be cached, but again there is a more natural way to write this outside the context of GraphQL.
@strawberry.type
class Query:
dictionary: Dictionary
def __init__(self):
self.dictionary = Dictionary()
Caching, context values, and root values are all clunky workarounds compared to the consistency of letting the root be Query() instead of Query. The applications which do not require this feature would never notice the difference.
The notion of “root fields” behaving as “top-level functions” has resulted in needless confusion, poorer API design, and incorrect implementations.
April 12, 2024 12:00 AM UTC
April 11, 2024
Are you new to Django development? Are you already familiar with it and want to expand your knowledge? PyCharm has Django learning resources for everyone. In this article, you’ll find a compilation of all the Django-related resources created by the experts at PyCharm to help you navigate through them all. From creating a new Django […]
April 11, 2024 10:53 AM UTC
If you've ever thought about starting a podcast or a SaaS project, you'll want to listen to this episode.
Justin is one of the people who motivated me to get started podcasting.
He's also running a successful SaaS company, transistor.fm, which hosts this podcast.
Topics:
- Podcasting
- Building new SaaS (software as a service) products
- Balancing work, side hustle, and family
- Great places to snowboard in British Columbia
BTW. This episode was recorded last summer before I switched to transistor.fm.
I'm now on Transistor for most of a year now, and I love it.
Links from the show:
Sponsored by Mailtrap.io
- An Email Delivery Platform that developers love.
- An email-sending solution with industry-best analytics, SMTP, an email API, SDKs for major programming languages, and 24/7 human support.
- Try for Free at MAILTRAP.IO
Sponsored by PyCharm Pro
The Complete pytest Course
- For the fastest way to learn pytest, go to courses.pythontest.com
- Whether your new to testing or pytest, or just want to maximize your efficiency and effectiveness when testing.
<p>If you've ever thought about starting a podcast or a SaaS project, you'll want to listen to this episode.<br> <br>Justin is one of the people who motivated me to get started podcasting. <br>He's also running a successful SaaS company, <a href="https://transistor.fm/?via=okken">transistor.fm</a>, which hosts this podcast.</p><p>Topics:</p><ul><li>Podcasting</li><li>Building new SaaS (software as a service) products</li><li>Balancing work, side hustle, and family</li><li>Great places to snowboard in British Columbia</li></ul><p>BTW. This episode was recorded last summer before I switched to <a href="https://transistor.fm/?via=okken">transistor.fm</a>.<br>I'm now on Transistor for most of a year now, and I love it.</p><p>Links from the show:</p><ul><li><a href="https://transistor.fm/?via=okken">Transistor.fm</a> - excellent podcast hosting, Justin is a co-founder</li><li><a href="https://transistor.fm/how-to-start-a-podcast/?via=okken">How to start a podcast in 2024</a></li><li>Podcasts from Justin<ul><li><a href="https://saas.transistor.fm/">Build your SaaS</a> - current</li><li><a href="https://www.buildandlaunch.net/">Build & Launch</a> - an older one, but great</li><li><a href="https://podcast.megamaker.co/">MegaMaker</a> - from 2021 / 2022</li></ul></li></ul>
<br><p><strong>Sponsored by Mailtrap.io</strong></p><ul><li>An Email Delivery Platform that developers love. </li><li>An email-sending solution with industry-best analytics, SMTP, an email API, SDKs for major programming languages, and 24/7 human support. </li><li>Try for Free at <a href="https://l.rw.rw/pythontest">MAILTRAP.IO</a></li></ul><p><strong>Sponsored by PyCharm Pro</strong></p><ul><li>Use code PYTEST for 20% off PyCharm Professional at <a href="https://www.jetbrains.com/pycharm/">jetbrains.com/pycharm</a></li><li>Now with Full Line Code Completion</li><li>See how easy it is to run pytest from PyCharm at <a href="https://pythontest.com/pycharm/">pythontest.com/pycharm</a></li></ul><p><strong>The Complete pytest Course</strong></p><ul><li>For the fastest way to learn pytest, go to <a href="https://courses.pythontest.com/p/complete-pytest-course">courses.pythontest.com</a></li><li>Whether your new to testing or pytest, or just want to maximize your efficiency and effectiveness when testing.</li></ul>
April 11, 2024 07:36 AM UTC
For the last several years, Spyder has offered standalone installers for Windows and macOS which isolate Spyder's runtime environment from users' development environments.
This provides a more stable user experience than traditional conda or pip installation methods.
However, these standalone installers did not allow implementing desirable features, such as automatic incremental updates or installing external Spyder plugins like Spyder-Notebook and Spyder-Unittest.
Additionally, these standalone applications were limited to Windows and macOS.
Our new installers will provide a more consistent experience for users across all platforms, including Linux, while maintaining the benefits of an isolated runtime environment for Spyder.
Additionally, they are fully compatible with incremental updates and external plugin management.
Look for future announcements about these and other features!
So, what will you see with these new installers?
If you are a Windows user, you will continue to have a graphical interface guiding you through the installation process, and will likely not notice any difference from the previous experience.
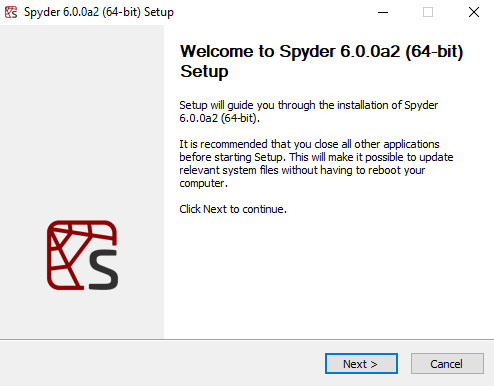
If you are a macOS user, you will now have a .pkg package installer instead of a .dmg disk image.
Rather than drag-and-drop the application to the Applications folder, the .pkg installer provides a graphical interface that will guide you through the installation process with more flexibility.
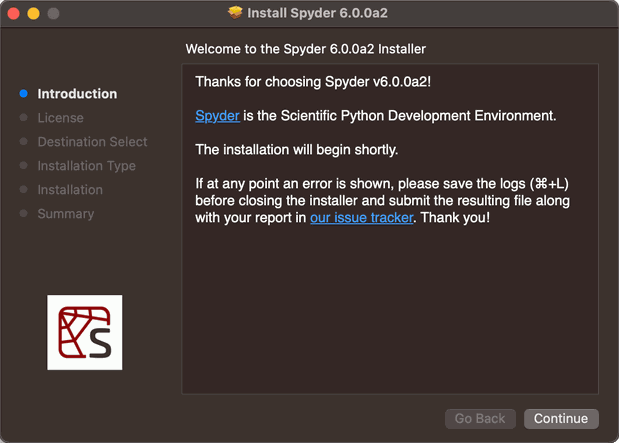
If you are a Linux user, you will have an interactive shell script guiding you through the installation process.
This ensures it is compatible with as many distributions and desktop environments as possible.
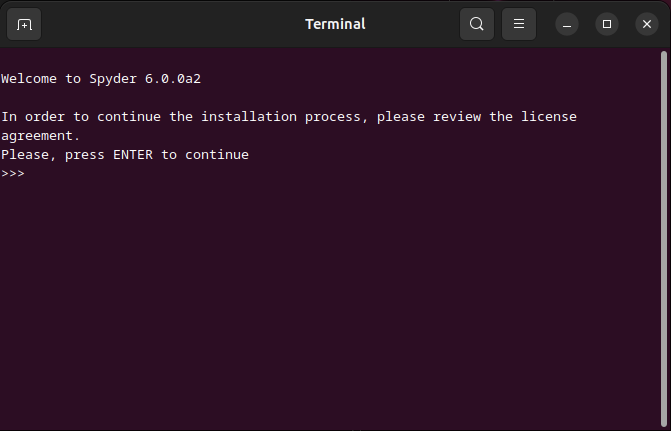
In all cases, you will not need to have Anaconda installed, nor do you need an existing Python environment; in fact, you don't even need a preexisting Python installation!
These installers are completely self-contained.
Spyder will continue to include popular packages such as NumPy, SciPy, Pandas and Matplotlib so you can start coding out-of-the-box.
However, you will still be able to use Spyder with your existing conda, venv, Python.org, and other Python installers and environments as before.
Furthermore, only Spyder and its critical dependencies will be updated on each new release, which will make getting the latest version a lean and frictionless process.
The Spyder team is really excited about these new installers and the new features they will make possible, and we hope you enjoy them too!
April 11, 2024 12:00 AM UTC
April 10, 2024

Let&aposs say that you&aposre working on a supervised Machine Learning problem, and you&aposre deciding how to encode the features in your training data.
With a categorical feature, you might consider using one-hot encoding or ordinal encoding. But with a continuous numeric feature, you would normally pass that feature directly to your model. (Makes sense, right?)
However, one alternative strategy that is sometimes used with continuous features is to "discretize" or "bin" them into categorical features before passing them to the model.
First, I&aposll show you how to do this in scikit-learn. Then, I&aposll explain whether I think it&aposs a good idea!
How to discretize in scikit-learn
In scikit-learn, we can discretize using the KBinsDiscretizer class:
When creating an instance of KBinsDiscretizer, you define the number of bins, the binning strategy, and the method used to encode the result:
As an example, here&aposs a numeric feature from the famous Titanic dataset:
And here&aposs the output when we use KBinsDiscretizer to transform that feature:
Because we specified 3 bins, every sample has been assigned to bin 0 or 1 or 2. The smallest values were assigned to bin 0, the largest values were assigned to bin 2, and the values in between were assigned to bin 1.
Thus, we&aposve taken a continuous numeric feature and encoded it as an ordinal feature (meaning an ordered categorical feature), and this ordinal feature could be passed to the model in place of the numeric feature.
Is discretization a good idea?
Now that you know how to discretize, the obvious follow-up question is: Should you discretize your continuous features?
Theoretically, discretization can benefit linear models by helping them to learn non-linear trends. However, my general recommendation is to not use discretization, for three main reasons:
- Discretization removes all nuance from the data, which makes it harder for a model to learn the actual trends that are present in the data.
- Discretization reduces the variation in the data, which makes it easier to find trends that don&apost actually exist.
- Any possible benefits of discretization are highly dependent on the parameters used with KBinsDiscretizer. Making those decisions by hand creates a risk of overfitting the training data, and making those decisions during a tuning process adds both complexity and processing time. As such, neither option is attractive to me!
For all of those reasons, I don&apost recommend discretizing your continuous features unless you can demonstrate, through a proper model evaluation process, that it&aposs providing a meaningful benefit to your model.
Going further
🔗 Discretization in the scikit-learn User Guide
🔗 Discretize Predictors as a Last Resort from Feature Engineering and Selection (section 6.2.2)
This post is drawn directly from my upcoming course, Master Machine Learning with scikit-learn. If you&aposre interested in receiving more free lessons from the course, please join the waitlist below:
April 10, 2024 03:12 PM UTC
Pydantic is a powerful data validation and settings management library for Python, engineered to enhance the robustness and reliability of your codebase. From basic tasks, such as checking whether a variable is an integer, to more complex tasks, like ensuring highly-nested dictionary keys and values have the correct data types, Pydantic can handle just about any data validation scenario with minimal boilerplate code.
In this tutorial, you’ll learn how to:
- Work with data schemas with Pydantic’s
BaseModel
- Write custom validators for complex use cases
- Validate function arguments with Pydantic’s
@validate_call
- Manage settings and configure applications with
pydantic-settings
Throughout this tutorial, you’ll get hands-on examples of Pydantic’s functionalities, and by the end you’ll have a solid foundation for your own validation use cases. Before starting this tutorial, you’ll benefit from having an intermediate understanding of Python and object-oriented programming.
Python’s Pydantic Library
One of Python’s main attractions is that it’s a dynamically typed language. Dynamic typing means that variable types are determined at runtime, unlike statically typed languages where they are explicitly declared at compile time. While dynamic typing is great for rapid development and ease of use, you often need more robust type checking and data validation for real-world applications. This is where Python’s Pydantic library has you covered.
Pydantic has quickly gained popularity, and it’s now the most widely used data validation library for Python. In this first section, you’ll get an overview of Pydantic and a preview of the library’s powerful features. You’ll also learn how to install Pydantic along with the additional dependencies you’ll need for this tutorial.
Getting Familiar With Pydantic
Pydantic is a powerful Python library that leverages type hints to help you easily validate and serialize your data schemas. This makes your code more robust, readable, concise, and easier to debug. Pydantic also integrates well with many popular static typing tools and IDEs, which allows you to catch schema issues before running your code.
Some of Pydantic’s distinguishing features include:
-
Customization: There’s almost no limit to the kinds of data you can validate with Pydantic. From primitive Python types to highly nested data structures, Pydantic lets you validate and serialize nearly any Python object.
-
Flexibility: Pydantic gives you control over how strict or lax you want to be when validating your data. In some cases, you might want to coerce incoming data to the correct type. For example, you could accept data that’s intended to be a float but is received as an integer. In other cases, you might want to strictly enforce the data types you’re receiving. Pydantic enables you to do either.
-
Serialization: You can serialize and deserialize Pydantic objects as dictionaries and JSON strings. This means that you can seamlessly convert your Pydantic objects to and from JSON. This capability has led to self-documenting APIs and integration with just about any tool that supports JSON schemas.
-
Performance: Thanks to its core validation logic written in Rust, Pydantic is exceptionally fast. This performance advantage gives you swift and reliable data processing, especially in high-throughput applications such as REST APIs that need to scale to a large number of requests.
-
Ecosystem and Industry Adoption: Pydantic is a dependency of many popular Python libraries such as FastAPI, LangChain, and Polars. It’s also used by most of the largest tech companies and throughout many other industries. This is a testament to Pydantic’s community support, reliability, and resilience.
These are a few key features that make Pydantic an attractive data validation library, and you’ll get to see these in action throughout this tutorial. Up next, you’ll get an overview of how to install Pydantic along with its various dependencies.
Installing Pydantic
Pydantic is available on PyPI, and you can install it with pip. Open a terminal or command prompt, create a new virtual environment, and then run the following command to install Pydantic:
This command will install the latest version of Pydantic from PyPI onto your machine. To verify that the installation was successful, start a Python REPL and import Pydantic:
If the import runs without error, then you’ve successfully installed Pydantic, and you now have the core of Pydantic installed on your system.
Adding Optional Dependencies
You can install optional dependencies with Pydantic as well. For example, you’ll be working with email validation in this tutorial, and you can include these dependencies in your install:
Pydantic has a separate package for settings management, which you’ll also cover in this tutorial. To install this, run the following command:
With that, you’ve installed all the dependencies you’ll need for this tutorial, and you’re ready to start exploring Pydantic. You’ll start by covering models—Pydantic’s primary way of defining data schemas.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
April 10, 2024 02:00 PM UTC
This tutorial explains the steps to open Google Chrome using Selenium in Python.
To read this article in full, please click here
April 10, 2024 08:05 AM UTC
CPython release automation, more Windows SBOMs
This critical role would not be possible without funding from the Alpha-Omega project. Massive thank-you to Alpha-Omega for investing in the security of the Python ecosystem!
CPython source and docs builds are automated in GitHub Actions
While I was away on vacation, the CPython Developer-in-Residence Łukasz was able to dry-run, review, and merge
my pull request
to automate source and docs builds in GitHub Actions on
the python/release-tools repository.
The automation was successfully used for the CPython 3.10.14, 3.11.9, 3.12.3, and 3.13.0a6.
This work being merged is exciting because it isolates the CPython
source and docs builds from individual release manager machines preventing those source
tarballs from being unintentionally modified. Having builds automated is a pre-requisite for
future improvements to the CPython release process, like adding automated uploads to python.org
or machine/workflow identities for Sigstore. I also expect the macOS
installer release process to be automated on GitHub Actions. Windows artifact builds are already using Azure Pipelines.
Release Managers have requested the process be further automated
which is definitely possible, especially for gathering the built release artifacts
and running the test suite locally.
Windows Software Bill-of-Materials coming for next CPython releases
I've been collaborating with Steve Dower to get SBOM documents generated
for Windows Python artifacts. Challenges of developing new CI workflows aside
we now have SBOM artifacts generating as expected.
Next step is to automate the upload of the SBOM documents to python.org so they've
automatically available to users.
During the development of Windows SBOMs I also noticed our CPE identifier for xz
was incorrect partially due to difficulties
using the CPE Dictionary search (they only allow 3+ character queries!) This issue doesn't
impact any existing published SBOM since xz-utils is only bundled with Windows artifacts, not source artifacts.
Thoughts on xz-utils
I've been a part of many discussions about xz-utils, both active and passive,
there are many thoughts percolating around our community right now. To capture
where I'm at with many of these discussions I wanted to write down my own thoughts:
- "Insider threats" and other attacks on trust are not unique to open source software.
We don't get to talk about other incidents as often because the attack isn't done in the open.
- Insider threats are notoriously difficult to defend against even with ample resources.
Volunteer maintainers shouldn't be expected to defend against patient and well-resourced attackers alone.
- Multiple ecosystems took action immediately, including Python,
to either remove compromised versions of xz or confirm they were not using affected versions.
This sort of immediate response should only be expected with full-time staffing (thanks Alpha-Omega!), but I know that volunteers were involved in the broader response to xz.
- Many folks, myself included, have remarked that this could have just as easily been them.
Reviewing the "Jia Tan" commits I can't say with certainty that I would have caught them
in code review, especially coming from a long-time co-maintainer.
How has the nature of open source affected the response to this event?
- Security experts were able to review source code, commits, conversations,
and the accounts involved immediately. We went from the public disclosure and alerts to having a timeline
of how the malicious account was able to gain trust within a few hours.
- We get to learn how the attack transpired in detail to hopefully improve in the future.
Things to keep in mind when working on solutions:
- Blaming open source software or maintainers is rarely the answer, and it definitely isn't the answer here.
- There isn't a single solution to this problem. We need both social and technical approaches, not exclusively one or the other.
Instead of pointing out how certain solutions or ways of supporting OSS "wouldn't have thwarted
this exact attack", let's focus on how the sum of contributions and support are
making attacks on open source more difficult in general.
- We need better visibility into critical languishing projects. xz likely wasn't on anyone's list of critical projects before this event (when it should have been!)
It isn't sustainable to figure out which projects are critical and need help
by waiting for the next newsworthy attack or vulnerability.
I also reflected on how my own work is contributing to one of many solutions to problems like this.
I've been focusing on reproducible builds, hardening of the CPython release process, and have been
working closely with Release Managers to improve their processes.
As I mentioned above, being full-time staff means I can respond quickly to events in the community.
The "all-clear" message for CPython, PyPI, and all Python packages was given a few hours after xz-utils
backdoor was disclosed to the Python Security Response Team.
I've also been working on Software Bill-of-Materials documents. These documents would not have done anything
to stop an attack similar to this, but would have helped users of CPython detect if they were using a vulnerable
component if the attack affected CPython.
Other items
- I'm attending SOSS Community Day and OSS Summit NA in Seattle April 15th to 19th. If you're there
and want to chat reach out to me! I spent time this week preparing to speak at SOSS Community Day.
- Added support for Python 3.13 to Truststore.
- Triaged reports to the Python Security Response Team.
That's all for this week! 👋 If you're interested in more you can read last week's report.
Thanks for reading! ♡ Did you find this article helpful and want more content like it?
Get notified of new posts by subscribing to the RSS feed or the email newsletter.
April 10, 2024 12:00 AM UTC
April 09, 2024
#624 – APRIL 9, 2024
View in Browser »
In this tutorial, you’ll learn about a tool called pipx, which lets you conveniently install and run Python packages as standalone command-line applications in isolated environments. In a way, pipx turns the Python Package Index (PyPI) into an app marketplace for Python programmers.
REAL PYTHON
In Python you can use the multiplication operator on sequences to return a repeated version of the value. When you do this with a list containing an empty list you get what might be unexpected behavior. This article explains what happens and why.
ABHINAV UPADHYAY
PEP 723 adds the ability to specify dependencies within a Python script itself. The folks who write pipx have added an experimental feature that takes advantage of this future language change. This article shows you how the new feature looks and what pipx does with it.
HENRY SCHREINER
Discussions
Articles & Tutorials
This post talks about the importance of naming conventions in your code, but takes it to the next level: use scripts to validate that conventions get followed. By using introspection you can write rules for detecting code that doesn’t follow your conventions. Examples are for Django fields but the concept works for any Python code.
LUKE PLANT
How do you customize a LLM chatbot to address a collection of documents and data? What tools and techniques can you use to build embeddings into a vector database? This week on the show, Calvin Hendryx-Parker is back to discuss developing an AI-powered, Large Language Model-driven chat interface.
REAL PYTHON podcast
The topic of multi-line lambdas, or anonymous functions akin to languages like JavaScript, comes up with some frequency in the Python community. It popped up again recently. This article talks about the history of the topic and the current reasoning against it.
JAKE EDGE
Maintaining code quality can be challenging no matter the size of your project or the number of contributors. Pre-commit hooks make it a little easier. This article provides a step-by-step guide to installing and configuring pre-commit hooks on your project.
STEFANIE MOLIN • Shared by Stefanie Molin
A code smell isn’t something that is necessarily broken, but could be a sign of deeper problems. This post teaches you how to identify and eliminate seven Python code smells with practical examples.
ARJAN
The PSF has joined with the Apache Software Foundation, the Eclipse Foundation, and other open source groups to form a group dedicated to cybersecurity initiatives in the open source community.
PYTHON SOFTWARE FOUNDATION
FastAPI is an excellent library and is quite popular in the Python community. Regardless of his respect for it, David still sticks with Django. This post discusses his ten reasons why.
DAVID DAHAN
Ensuring accessibility in your software is important, removing boundaries that limit some people from participating. This checklist is valuable for helping you determine whether your web code meets the accepted Web Content Accessibility Guidelines.
SARAH ABEREMANE
PyTorch vs Tensorflow: Which one should you use? Learn about these two popular deep learning libraries and how to choose the best one for your project.
REAL PYTHON course
Hynek talks about his Python tooling choices and how they’ve changed over the years, with a focus on environment management tools like uv and direnv.
HYNEK SCHLAWACK
Hamuko decided to try out rye. This post goes into detail about what worked and what didn’t for them.
HAMUKO
Projects & Code
Events
Happy Pythoning!
This was PyCoder’s Weekly Issue #624.
View in Browser »

[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
April 09, 2024 07:30 PM UTC
The
PSF is pleased to announce its fourth batch of PSF Fellows for 2023! Let
us welcome the new PSF Fellows for Q4! The following people continue to
do amazing things for the Python community:
Jelle Zijlstra
Thank you for your continued contributions. We have added you to our Fellow roster online.
The
above members help support the Python ecosystem by being phenomenal
leaders, sustaining the growth of the Python scientific community,
maintaining virtual Python communities, maintaining Python libraries,
creating educational material, organizing Python events and conferences,
starting Python communities in local regions, and overall being great
mentors in our community. Each of them continues to help make Python
more accessible around the world. To learn more about the new Fellow
members, check out their links above.
Let's
continue recognizing Pythonistas all over the world for their impact on
our community. The criteria for Fellow members is available online: https://www.python.org/psf/fellows/.
If you would like to nominate someone to be a PSF Fellow, please send a
description of their Python accomplishments and their email address to
psf-fellow at python.org. Quarter 1 nominations are currently in review.
We are accepting nominations for Quarter 2 2024 through May 20,
2024.
Are you a PSF Fellow and want to help the Work Group review nominations? Contact us at psf-fellow at python.org.
April 09, 2024 04:59 PM UTC
It’s time to eclipse the Python 3.11.9 release with two releases, one of which is the very last alpha release of Python 3.13:
Python 3.12.3
300+ of the finest commits went into this latest maintenance release
of the latest Python version, the most stablest, securest, bugfreeest we
could make it.
https://www.python.org/downloads/release/python-3123/
Python 3.13.0a6
What’s that? The last alpha release? Just one more month until
feature freeze! Get your features done, get your bugs fixed, let’s get
3.13.0 ready for people to actually use! Until then, let’s test with
alpha 6. The highlights of 3.13 you ask? Well:
- In the interactive interpreter, exception tracebacks are now colorized by default.
- A preliminary, experimental JIT was added, providing the ground work for significant performance improvements.
- The (cyclic) garbage collector is now incremental, which should mean shorter pauses for collection in programs with a lot of objects.
- Docstrings now have their leading indentation stripped, reducing memory use and the size of .pyc files. (Most tools handling docstrings already strip leading indentation.)
- The dbm module has a new dbm.sqlite3 backend that is used by default when creating new files.
- PEP 594 (Removing dead batteries from the standard library) scheduled removals of many deprecated modules:
aifc, audioop, chunk, cgi, cgitb, crypt, imghdr, mailcap, msilib, nis, nntplib, ossaudiodev, pipes, sndhdr, spwd, sunau, telnetlib, uu, xdrlib, lib2to3. - Many other removals of deprecated classes, functions and methods in various standard library modules.
- New deprecations, most of which are scheduled for removal from Python 3.15 or 3.16.
- C API removals and deprecations. (Some removals present in alpha 1 were reverted in alpha 2, as the removals were deemed too disruptive at this time.)
(Hey, fellow core developer, if a feature you find important is missing from this list, let Thomas know. It’s getting to be really important now!)
https://www.python.org/downloads/release/python-3130a6/
We hope you enjoy the new releases!
Thanks to all of the many volunteers who help make Python Development
and these releases possible! Please consider supporting our efforts by
volunteering yourself, or through contributions to the Python Software Foundation or CPython itself.
Thomas “can you tell I haven’t had coffee today” Wouters
on behalf of your release team,
Ned Deily
Steve Dower
Pablo Galindo Salgado
Łukasz Langa
April 09, 2024 03:16 PM UTC
Anaconda has announced a new partnership with Teradata to bring Python and R packages to Teradata VantageCloud through the Anaconda Repository.
But what does that mean? This new partnership allows engineers to:
- Rapidly deploy and operationalize AI/ML developed using open-source Python and R packages.
- Unlock innovation and the full potential of data at scale with a wide variety of Python and R functionality on VantageCloud Lake.
- Flexibly use packages and versions of their choice for large-scale data science, AI/ML and generative AI use-cases.
- Securely work with Python/R models into VantageCloud Lake with no intellectual property (IP) leakage.
Teradata VantageCloud Lake customers can download Python and R packages from the Anaconda Repository at no additional cost. Python packages are available immediately, and R packages will be released before the end of the year.
For more information about Teradata ClearScape Analytics, please visit Teradata.com.
Learn more about partnering with Anaconda here.
The post Anaconda Partners with Teradata for AI with Python packages in the Cloud appeared first on Mouse Vs Python.
April 09, 2024 02:04 PM UTC
From restaurant e-menus to airline boarding passes, QR codes have numerous applications that impact your day-to-day life and enrich the user’s experience. Wouldn’t it be great to make them look good, too? With the help of this video course, you’ll learn how to use Python to generate beautiful QR codes for your personal use case.
In its most basic format, a QR code contains black squares and dots on a white background, with information that any smartphone or device with a dedicated QR scanner can decode. Unlike a traditional bar code, which holds information horizontally, a QR code holds the data in two dimensions, and it can hold over a hundred times more information.
In this video course, you’ll learn how to:
- Generate a basic black-and-white QR code
- Change the size and margins of the QR code
- Create colorful QR codes
- Rotate the QR code
- Replace the static background with an animated GIF
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
April 09, 2024 02:00 PM UTC






